-

Autodesk Ember SLA (Resin) 3D Printer – Findings, Document Dump and new Slicer!
Or: Tim reverse-engineers an open-source product to reconstruct the open-source materials! Long story short, I picked up this Autodesk “open-source” (words I thought I would never hear together) stereolithography printer at a local freecycle event. I thought it was a vacuum cleaner until I saw the Autodesk name on the back label. On realizing what…
-
Kalmbach Media / Discover Magazine Subscription Scam
Hello friends from the search engines! If you’re reading this, you’re not the only one to receive one. With apologies in advance for turning this blog into an archive of my snail-mail, here is an “invoice” I got the other day, for a magazine I used to have a gift subscription to years-and-years ago. As…
-

Build a Minimalist DIY Vibratory Rock Tumbler
My son and I have gotten into rock tumbling a bit, so I put a small vibratory tumbler on my “would be nice” holiday wishlist. So, apparently this hobby has gotten popular lately and these things can’t be had for love or money. Maybe for lots of money, but I wasn’t ready to drop 400…
-

Enshittification, the honeymoon phase and the Great Throttle Map Conspiracy
By now, you have probably heard a thing or two about enshittification – the process by which online platforms lure a customer base with favorable terms, then gradually sour the deal once users are locked in. Often, this involves a multilevel game of “the customer is the product”, or as Cory Doctorow puts it: This…
-
KoolStone Rock Tumbler Replacement Belt sourcing
A very quick note to my future self: AFAICT the KoolStone (iKoolStone?) belts are plain rubber O-rings, which come in standardized size numbers. For the KoolStone (C1? 2.5lb capacity) rock tumbler, it is size 231 (approximately 2-5/8″ ID, 2-7/8″ OD, 1/8″ width). Durometer unknown, but 50A durometer seems to be working well. These can be…
-

Pandemic Project: Aquascaping with Insulating Foam & Found Objects
“The pandemic is over!”, says the world, as I sit here cooped up in a household full of COVID and no childcare :p Anyway, a bit late writing this up, but when the actual COVID lockdowns were going strong and everyone needed hobbies, I decided to put together a nice fishtank aquascape using mostly stuff…
-
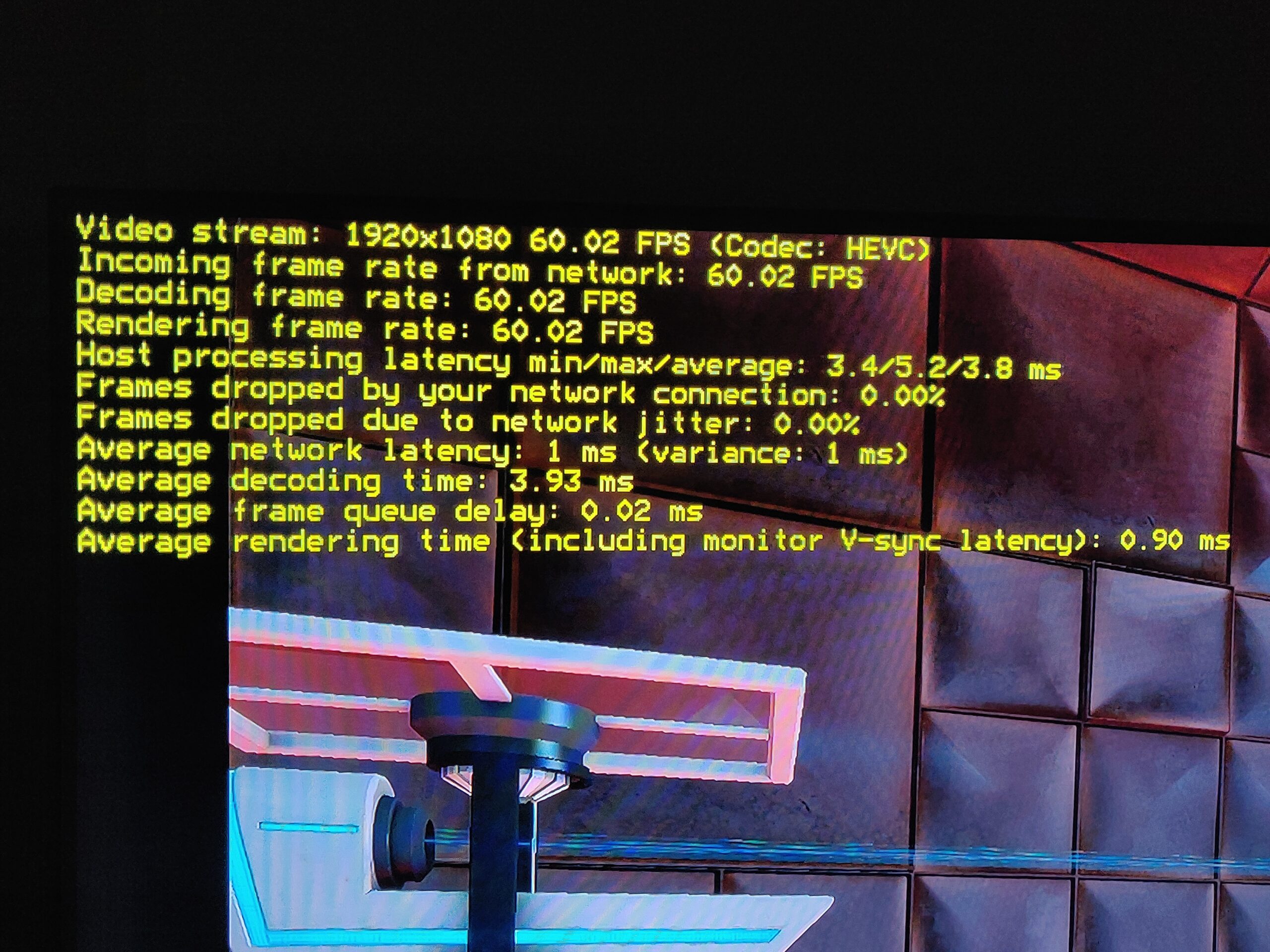
Notes To Myself: Remote Couch Gaming with RPI5 / Moonlight
Hey Future Tim, in case you ever need to set it up again, here is a guide to setting up game streaming from a beefy desktop PC (game host / backend) to a Raspberry Pi 5 (game display client / frontend) with low latency, both for the input devices (keyboard/mouse or controllers linked to the…
-

3D-Printable replacement plastic coupler bit (stem driver) for Kohler Rite-Temp(R) shower faucet handles
Go for a shower, and the new (professionally installed just over 1 year ago) Kohler shower faucet handle just spins in a full circle with some rough detents without any water coming out. After figuring out what the actual product is and how to extract it from the wall (nary a screw or screw-hiding cover…
-
Exactly how much work is a half-assed job?
If you tend to work smarter, not harder, you may at some point in your life have been accused of doing a half-assed job. But what, exactly, does that mean? How much work are you doing? How much energy are you putting into it?
-
Not enough ass in your pants?
Growing up, when someone was attempting a job that was clearly too big for them, my uncle would say: “You don’t have enough ass in your pants for that!” What this expression meant of course was that all the strength, gumption or determination in the world were irrelevant, and the task at hand just required…
-
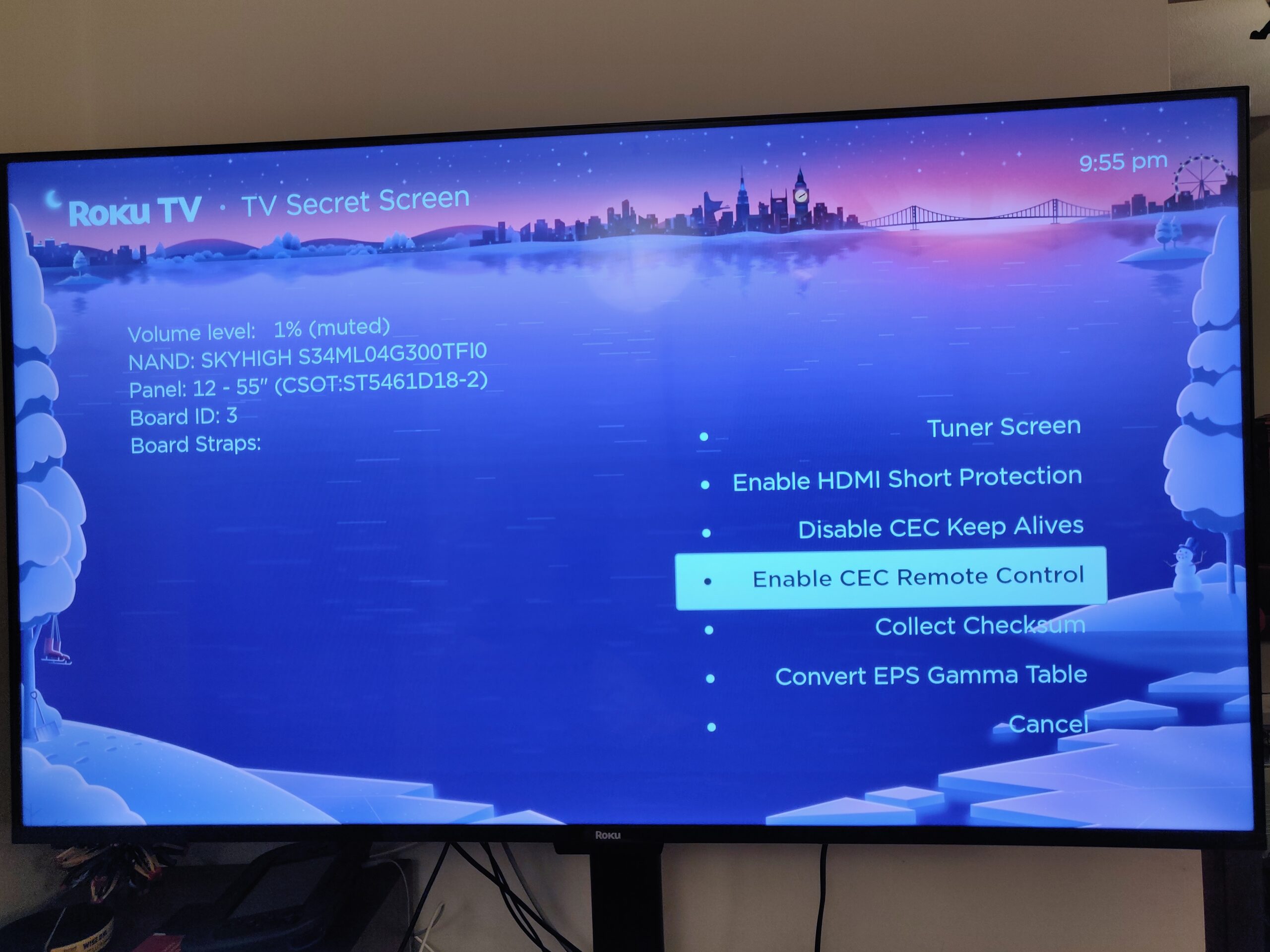
Solved: Control Raspberry Pi media center (Kodi) with Roku TV’s remote over HDMI CEC
TL;DR if you already figured out the documented stuff: Enable 2-way CEC (keypresses from TV remote to attached device) in the Roku secret menu: Quickly (within ~ 5 seconds) press Home 5 times, rewind, down, fast forward, down, rewind, and “Enable CEC Remote Control”. A further update: After doing all this, I found Kodi on…
-
MAPFRE Data Breach, or, “What’s a MAPFRE and why do they have my information?”
So, I had this brilliant idea for a legitimate passive income opportunity: Start a company with an online presence and terrible information security. Buy personal information in bulk, store copies of it on our servers, then sit back as eeevil hackers steal it. Repeatedly. Each time it happens, offer the affected customers 12 months of…
-

Spookifying Haunted Mirror build using Stable Diffusion
For this Halloween, I built this haunted mirror display for the porch that turns any trick-or-treaters extra spooky. Using the voodoo power of AI, those who gaze into the mirror will be treated to a visage of their best Halloween self. See below for code and build tips if you’re interested in making your own!…
-
Solved: Use Roku TV (Class Select Series 4K Smart TV) without internet access
We begin today with a rant on the cancer on society that is hardware-as-a-service and forced obsolescence, in a time when terms like “climate crisis” are casually bantered about on the evening news… possibly as a diversion to avoid talking about actual cancer, but that’s neither here nor there :-( Anyway, what you came for:…
-

Fixing Dell Ultrasharp (U3014/U3014T) Monitor Not Working (Now with Firmware!)
So, I found this lovely behemoth in my work’s e-waste pile and yanked it out, figuring on harvesting a nice big diffuser and backlight for a different project. But a quick search on the partnumber showed this thing is pretty impressively specced, and maybe I’d rather have a go at getting it running again instead.…
-
Solved: YouTube Watch Later ‘Remove Watched’ missing 2021
TL;DR: Watch one of the first 10 videos in your “Watch Later” list and see if it magically reappears. Doing a web search for this problem reveals it has been an issue for some time, but possibly for varying reasons in the past. The above is working for me on Web + native clients as…
-

Sticky Nano Heater, a small fishtank heater that stays dry
While procrastinating on my current year+ long “couple long weekends” project, in which I’ve clearly bitten off more than a post-kids me has time to chew, I set my sights on a stupid-simple project I could actually complete :-) This is an adhesive stick-on fish tank heater for nano aquariums. The thin PCB trace heater…
-

Potential Safety Flaw in Home Depot HDX brand wire shelving units
Asbestos undergarments? Check. Lawyer-proof socks? Check. Here we go. I got a small safety lesson over the weekend I wanted to share. Officially, it’s about an extremely common design of wire-rack shelving units, but the real safety lesson is to double-check the workmanship of load-bearing products with a critical eye, because the manufacturer may not…
-

Tim Tears It Apart: SunGrow Betta Heater, a Sketchy Preset Aquarium Heater
Spoiler alert time. Did you know there are ferrous metal composites with arbitrary Curie points, extending down to room temperature and even below freezing? You never know where a teardown of a theoretically boring product will lead. Seriously, take more stuff apart, it’s good for you. I’ll spare you the lengthy story of the goldfish…
-

Other Utricularia for aquascaping besides UG
Utricularia graminifolia (UG) is a popular foreground plant for planted aquariums, with grass-like leaves that eventually form a lush green carpet over the substrate. It is considered anywhere between easy and impossible to grow, and has some special needs that make it not a beginner’s plant. However, there are a whole range of Utricularia that…
Find stuff…
Pages
- Das Blinkenlichten – wearable lighting
- Goldmine Electronics LCD pinout (mini-teardown)
- Mosquino: an Arduino-based energy harvesting development board
- Pick and Place Project
Categories
Tags
blinkenlichten broken brokenbydesign circuit bending cnc codebending comcast corporates crashes dell error evil foodz freezes gadget garden glitch music groan hangs humor idiocy led lirc machine meme NES norrisolide pickplace precision python recipe reprap rgb salesdouche serial stupidity sucks t3400 teardown ticket timtearsitapart usb webcam windows xp