-
Solved: Use Roku TV (Class Select Series 4K Smart TV) without internet access
We begin today with a rant on the cancer on society that is hardware-as-a-service and forced obsolescence, in a time when terms like “climate crisis” are casually bantered about on the evening news… possibly as a diversion to avoid talking about actual cancer, but that’s neither here nor there :-( Anyway, what you came for:
-

Fixing Dell Ultrasharp (U3014/U3014T) Monitor Not Working (Now with Firmware!)
So, I found this lovely behemoth in my work’s e-waste pile and yanked it out, figuring on harvesting a nice big diffuser and backlight for a different project. But a quick search on the partnumber showed this thing is pretty impressively specced, and maybe I’d rather have a go at getting it running again instead.
-
Solved: YouTube Watch Later ‘Remove Watched’ missing 2021
TL;DR: Watch one of the first 10 videos in your “Watch Later” list and see if it magically reappears. Doing a web search for this problem reveals it has been an issue for some time, but possibly for varying reasons in the past. The above is working for me on Web + native clients as
-

Sticky Nano Heater, a small fishtank heater that stays dry
While procrastinating on my current year+ long “couple long weekends” project, in which I’ve clearly bitten off more than a post-kids me has time to chew, I set my sights on a stupid-simple project I could actually complete :-) This is an adhesive stick-on fish tank heater for nano aquariums. The thin PCB trace heater
-

Potential Safety Flaw in Home Depot HDX brand wire shelving units
Asbestos undergarments? Check. Lawyer-proof socks? Check. Here we go. I got a small safety lesson over the weekend I wanted to share. Officially, it’s about an extremely common design of wire-rack shelving units, but the real safety lesson is to double-check the workmanship of load-bearing products with a critical eye, because the manufacturer may not
-

Tim Tears It Apart: SunGrow Betta Heater, a Sketchy Preset Aquarium Heater
Spoiler alert time. Did you know there are ferrous metal composites with arbitrary Curie points, extending down to room temperature and even below freezing? You never know where a teardown of a theoretically boring product will lead. Seriously, take more stuff apart, it’s good for you. I’ll spare you the lengthy story of the goldfish
-

Other Utricularia for aquascaping besides UG
Utricularia graminifolia (UG) is a popular foreground plant for planted aquariums, with grass-like leaves that eventually form a lush green carpet over the substrate. It is considered anywhere between easy and impossible to grow, and has some special needs that make it not a beginner’s plant. However, there are a whole range of Utricularia that
-
Disable automatic reboots on Windows 10 (maybe)
Look, I get it, updates are important, and so is installing them timely. But after waking up this morning to find yet-another overnight job lost to an automatic reboot, it’s the last straw. To afford nice things (you know, like computers), I need to do my job, and that requires actually using my computer and
-
Notes To Myself: Fixing File Sharing in Windows 10 after “Fall Creators Update” breaks it
About 2 years ago, sharing movies from my desktop (Windows 10, alas) to the old Linux Mint laptop acting as a Chromecast-that-plays-local-content-without-weird-workarounds randomly stopped working, with Gigolo reporting the very helpful error, “Connection timed out”. Fair enough, it’s not Gigolo’s job to diagnose problems caused by dodgy Windows updates. After more Googling than it should
-
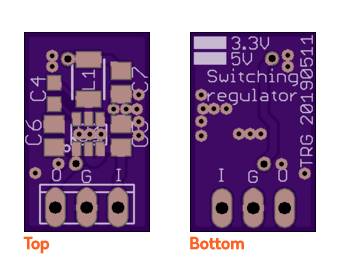
Silly Subproject: Switching 7805 / 7833 TO-220 replacement
Thanks to an oopsie on a larger project that involved not doing the math before dropping a small 3.3V linear regulator into a >20V input circuit design, I had a need to swap it for something that generated less finger-burning, board-cooking, smoky-smelling heat. I’m sure everyone and their dog has done one of these already,
-
Not Dead
I’ve just been busy with a couple of little things. Now that the littlest one is figuring out this whole sleep thing, I might have time for projects again :-)
-
Hooah! Could your next MRE contain bug meat?
This delicious solicitation for an upcoming DARPA project rolled …er, scuttled? across my desk last week. Now, I’m no stranger to unconventional protein sources with way too much exoskeleton, but this project might be food for thought if you plan to enlist. Excerpts, emphasis mine: Component: DARPA Topic #: SB172-002 Title: Improved Mass Production of
-
Solved: Mazda (JCI) Infotainment crashes when playing OGG Vorbis files
The Fix (Tl;dr): The Mazda Connect (a.k.a. “JCI infotainment” or Johnson Controls Infotainment, etc.) firmware available as of 1/2016 has a problem with long tags in Ogg Vorbis files, specifically the tags used for album/cover art. Vorbis files containing cover art will likely cause the radio to freeze and then reboot. To fix this, you
-
Free IoT Telemetry using DNS Tunneling and Other Peoples’ WiFi (Part 1)
Well, it happened. Despite all my talk about “Internet of Things” hype being teh suck and not ready for primetime yet, I’m now an official IoT Hero. I suppose I should actually do something about that. Today, we explore cheap-as-free data exfiltration for mobile IoT gadgets using a trick known as DNS tunneling. Internet of
-
Notes To Myself: Starting out with OpenWSN (Part 1)
TL;DR: Successful toolchain setup, flashing and functional radio network! Still todo: Fix network connectivity between the radio network and host system, and find/fix why the CPUs run constantly (drawing excess current) instead of sleeping. Over the last few weeks (er, months?), I build up and tried out some circuit boards implementing OpenWSN, an open-source low-power
-
Clutter, Give Me Clutter (or, a GUI that doesn’t use Google as an externalized commandline)
UX nightmare: Get the menu at a restaurant, and it has only 2 items: toast and black coffee. But if you spindle the corner just right, a hidden flap pops out with a dessert menu. And if you shake it side to side, a card with a partial list of entrees falls in your lap
-
Tim Tears It Apart: Measurement Specialties Inc. 832M1 Accelerometer
So, yesterday the outdoors turned into this. Not quite the snowpocalypse, but it was enough that a travel ban was in effect, and work was closed. What happens when we’re stuck in the house with gadgets? All right, I’d like to tell you that’s the reason, but this actually got broken open accidentally at my
-
Tim Tears It Apart: Koolpad Qi Wireless Charger (Also: how to silence it without soldering)
My wife goes to bed long before me, so when I go to bed, it behooves me to do so without significant light or racket. After countless nights of fiddling with a 3-sided micro-USB cable in the dark, I bought this neat little USB phone charger. It’s not the cheapest, nor the priciest, but was
-
Tim Tears It Apart: Cheap Solar Pump
So, I picked up a pair of these cheapo solar pump on fleabay for about 6 or 8 bucks a pop, to filter water for the fish in my old-lady-swallowed-a-fly lotus pot. They actually work pretty well, apart from one very occasionally getting stuck and needing a spin by hand to get going. But it’s
-
Notes To Myself: Cheap Feedlines for Cheap Boards
Goal: Produce reasonable impedance-matched (usually 50-ohms) RF feedlines for hobby-grade radio PCBs. Rather than get a PhD in RF engineering for a one-off project, use an online calculator and some rules of thumb to get a “good enough” first prototype. Problem: Most RF boards and stripline calculators assume or drive toward 4-layer boards. In hobby
Find stuff…
Pages
- Das Blinkenlichten – wearable lighting
- Goldmine Electronics LCD pinout (mini-teardown)
- Mosquino: an Arduino-based energy harvesting development board
- Pick and Place Project
Categories
Tags
3dprinting ai blinkenlichten broken brokenbydesign circuit bending cnc codebending comcast corporates crashes dell error evil foodz gadget garden glitch music groan humor idiocy led lirc machine meme NES norrisolide pickplace precision python recipe reprap rgb salesdouche serial stupidity sucks t3400 teardown ticket timtearsitapart usb webcam windows xp