Well, it happened. Despite all my talk about “Internet of Things” hype being teh suck and not ready for primetime yet, I’m now an official IoT Hero. I suppose I should actually do something about that. Today, we explore cheap-as-free data exfiltration for mobile IoT gadgets using a trick known as DNS tunneling.

Internet of Toilets, data exfiltration and wardriving!
Suppose you are a company that rents, leases, or otherwise loans out large numbers of some mobile object that you hope to get back at some point… say, Port-a-Potties Port-a-Johns Portaloos Honey Buckets portable toilets (yes, this is based on a true story). As it happens, they often get lost, stolen, blown away, forgotten somewhere or simply lost track of somewhere in your own logistics chain. This happens more than you might think, with various computer glitches or simple human screwups leaving inventory trapped on trucks or lost right under your nose in your own warehouse.
As a world leader in mobile outhouses with over 1 meeeelion units in circulation worldwide, you can’t afford to have your product going walkabout all the time, so you’d like to tag them with a bit of battery-powered IoT smarts so they can report back their locations periodically. A FindMyCrapper app tied into your logistics would let you opportunistically round up your lost sheep on the way by and bring them home.
So, we have 2 needs:
1) Get the location of the object periodically
2) Phone it home
This applies to whatever object you’d like back, including toilets, dumpsters, lighted traffic devices, reusable shipping containers… Housepets too if you can convince them to wear it.
The tried-and-mostly-true approach for #1 is GPS, with the caveat that it won’t work well, if at all, indoors (including units lost in your distribution center) or under dense cover. For #2 (hah!) it’s cellular. You can get a uBlox module for $35USD that covers this as well as free access to their cell triangulation database, which will provide rudimentary location, even indoors. Off-brand cell modems from the usual sources can probably be had for much less. Just beware of the cost of connectivity, especially if you’re not a big enough fish to sweet-talk your way out of per-device maintenance charges (I omit satellite options for just this reason). Also, as anyone living outside metropolitan areas can attest, coverage outside metropolitan areas can be iffy. So ideally, we want a cheap backup option for both of these needs.
Seeing as you can now get ludicrously cheap WiFi modules (like the infamous $2 ESP8266) and run them indefinitely (if infrequently) with a small solar cell and rechargeable battery, they scream possibilities. If you could use random WiFi access points nearby to (a) triangulate trilaterate your location and (b) phone it home, you’d be in business. We know WiFi geolocation is a thing (Apple and Google are doing it all the time), but sneaking data through a public hotspot without logging in?
To find out, I ran a little experiment with a Raspberry Pi in my car running a set of wardriving scripts. As I went about my daily business, it continuously scanned for open access points, and for any it was able to connect to, tried to pass some basic data about the access point via DNS tunneling*, a long-known but recently-popular technique for sneaking data through captive WiFi portals. Read the footnote if you’re interested in how this works!
The Experiments
Since I’m pressed for freetime and this is just a quick proof-of-concept, I used a Raspberry Pi, WiFi/GPS USB dongles and bashed together some Python scripts rather than *actual* tiny/cheap/battery-able gear and clever energy harvesting schemes (even if that is occasionally my day job). The scripts answer some key questions about WiFi geolocation and data exfiltration. All of the scripts and some supporting materials are uploaded on GitHub (WiSneak).
1) Can mere mortals (not Google) viably geolocate things using public WiFi data? How good is it compared to GPS? Is it good enough to find your stuff?
The ‘wifind’ script in scanning mode grabs the list of visible access points and signal strengths, current GPS coordinate, and the current time once per second, and adds it to a Sqlite database on the device. Later (remember, lazy and proof of concept), another script, ‘query-mls’ reads the list of entries gathered for each trip, queries the Mozilla Location Service with the WiFi AP data to get lat/lon, then exports .GPX files of the WiFi vs. GPS location tracks for comparison.
There are other WiFi location databases out there (use yer Googler), but most are either nonfree (in any sense of the word) or have very limited or regional data. MLS seemed to have an answer for every point I threw at it. The only real catch is you have to provide at least 2 APs in close physical proximity as a security measure – you can’t simply poke in the address of a single AP and get a dot on the map.
2) Just how much WiFi is out there? How many open / captive portal hotspots? How many of them are vulnerable to DNS tunneling?
A special subdomain and DNS record were set up on my web host (cheap Dreamhost shared hosting account) to delegate DNS requests for that subdomain to my home server, running a DNS server script (‘dnscatch’) and logging all queries. This is the business end end of the DNS tunnel.
In tunnel discovery mode, ‘wifind’ repeatedly scans for unencrypted APs and checks if their tunneling status is known yet. If unknown APs are in range, it connects to the one with the highest signal strength, and progresses through the stages of requesting an address (DHCP), sending a DNS request (tunnel probe with short payload), validating the response (if any) against a known-good value, and finally, fetching a known Web page and validating the received contents against the expected contents. The AP is considered ‘known’ if all these evaluations have completed, or if they could not be completed in a specified number of connection attempts. The companion script, ‘dnscatch’ running on a home PC (OK, another RasPi… yes I have a problem) catches the tunneled probe data and logs it to a file. The probe data includes the MAC address and SSID of the access point it was sent through. Finally, ‘query-mls’ correlates the list of successfully received tunneled data with the locations where the vulnerable AP was in range, outputting another set of .GPX files with these points as POI markers.
Preliminary Results
This is expected to be an ongoing project, with additional regional datasets captured and lots of statistics. I haven’t got ’round to any of that yet, but here is a look at some early results.
All of the map images below were made by uploading the resulting .GPX files into OpenStreetMaps’ uMap site, which hosts an open-source map-generation tool (also) called uMap. Until finding this, I thought generating the pretty pictures would end up being the hardest part of this exercise.

This trip, part of my morning commute (abridged in the map image), consists of 406 total GPS trackpoints and 467 WiFi trackpoints (the lower figure for GPS is due to the time it takes to fix after a cold start). Of these, 238 (51%) were in view of a tunnelable AP. The blue line is the “ground truth” GPS track and the purple line with dots is the track estimated from WiFi geolocation showing the actual trackpoints (and indirectly, the distribution of WiFi users in the area). The red dots indicate trackpoints where a tunneling-susceptible AP was in-view, allowing (in a non-proof-of-concept) live and historical telemetry to be exfiltrated by some dirty WiFi moocher.
Overall, the WiFi estimate is pretty good in an urban residential/commercial setting, although it struggles a bit here due to the prevalence of big parking lots, cinderblock industrial parks and conservation areas. The apparent ‘bias’ in the data toward WiFi-less areas in this dataset is consistent, based on comparison to the return drive, and does not appear to be an artifact of e.g. WiFi antenna placement on the left vs. right side of the Pi.
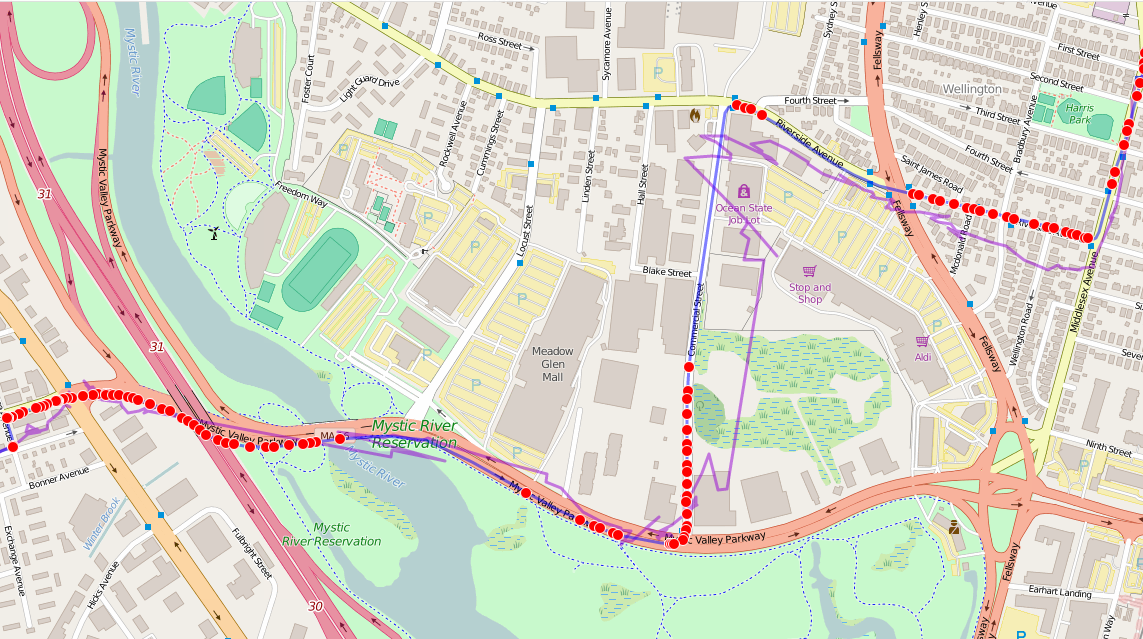
Here is basically the same thing, with the tunnelable points shown according to the ground-truth GPS position track rather than the WiFi location track.
How does it do under slightly more challenging WiFi conditions?
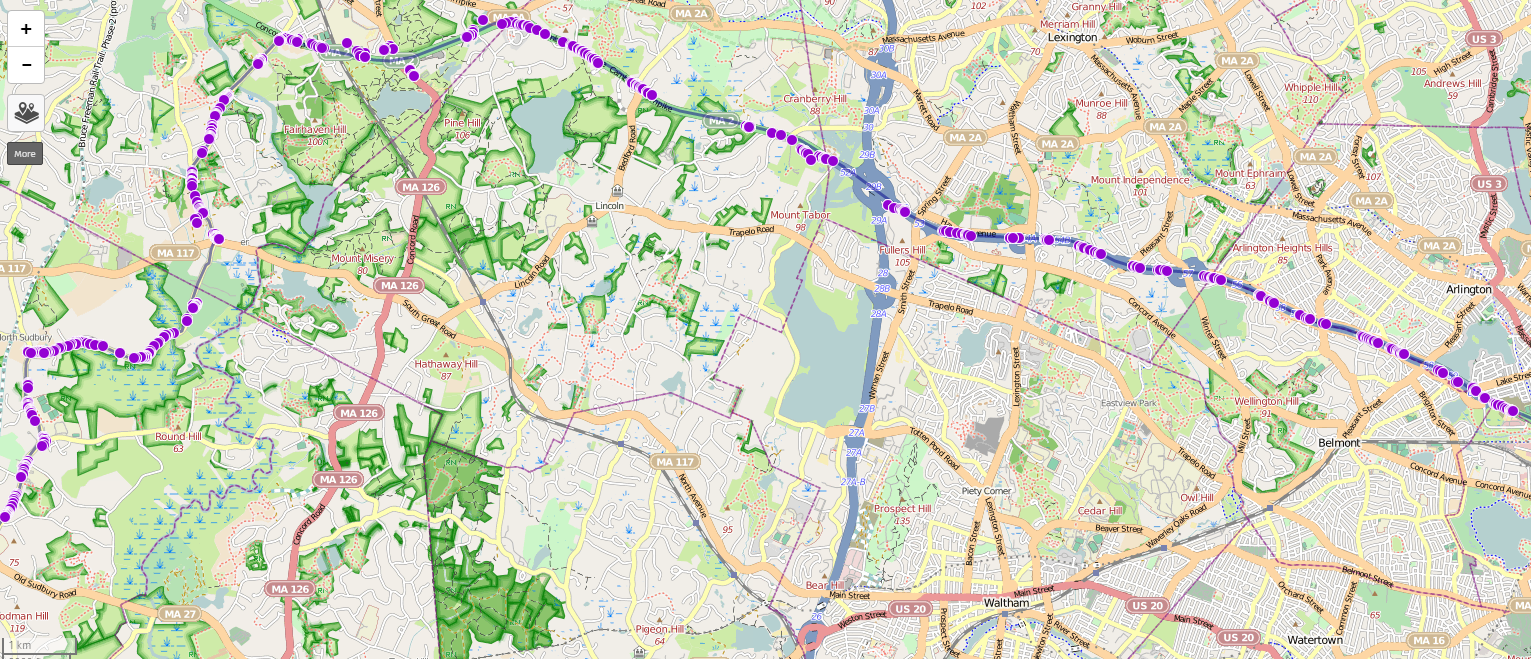
Here is another dataset, taken while boogeying down MA-2 somewhere north of the posted speed limit. Surprisingly, the location accuracy is pretty good in general, even approaching proper highway speeds. This is the closest thing I have to a “highway” dataset, due to just now finishing up the scripts and not having a chance to actually drive on any yet. It will be interesting to see how many significant locatable APs can be found on a highway surrounded by cornfields instead of encroaching urban sprawl. I suspect there are a few lurking in various taffic/etc. monitoring systems and AMBER alert type signage scattered about, but they may not be useful for locating (with MLS, at least) due to the restriction of requiring at least two APs in-view to return a position. This is ostensibly to prevent random Internet loonies from tracking people to their houses via their WiFi MACs, although I have no idea how one would actually accomplish that (at least in an easier way than just walking around watching the signal strength numbers, which doesn’t require MLS at all). Unfortunately, I don’t have tunneling data for this track since I haven’t driven it with the script in tunnel discovery mode yet.
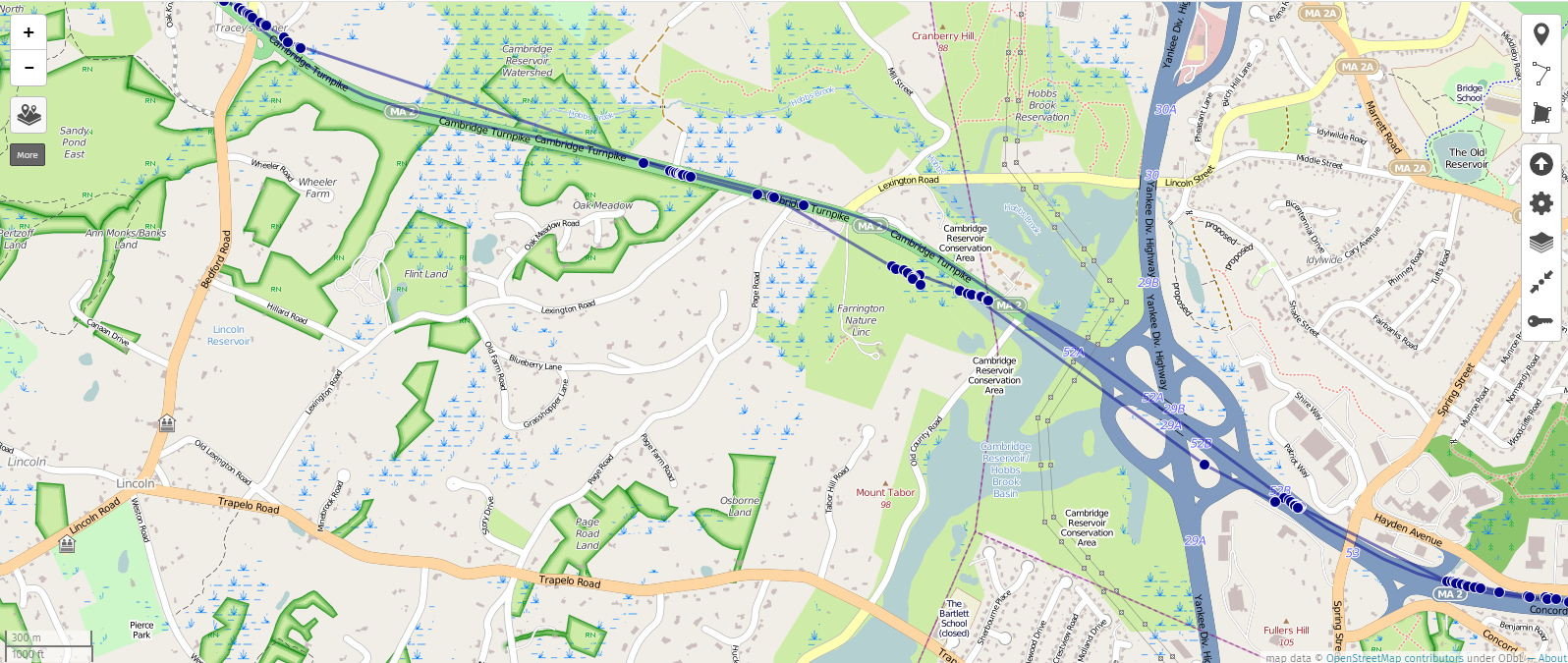
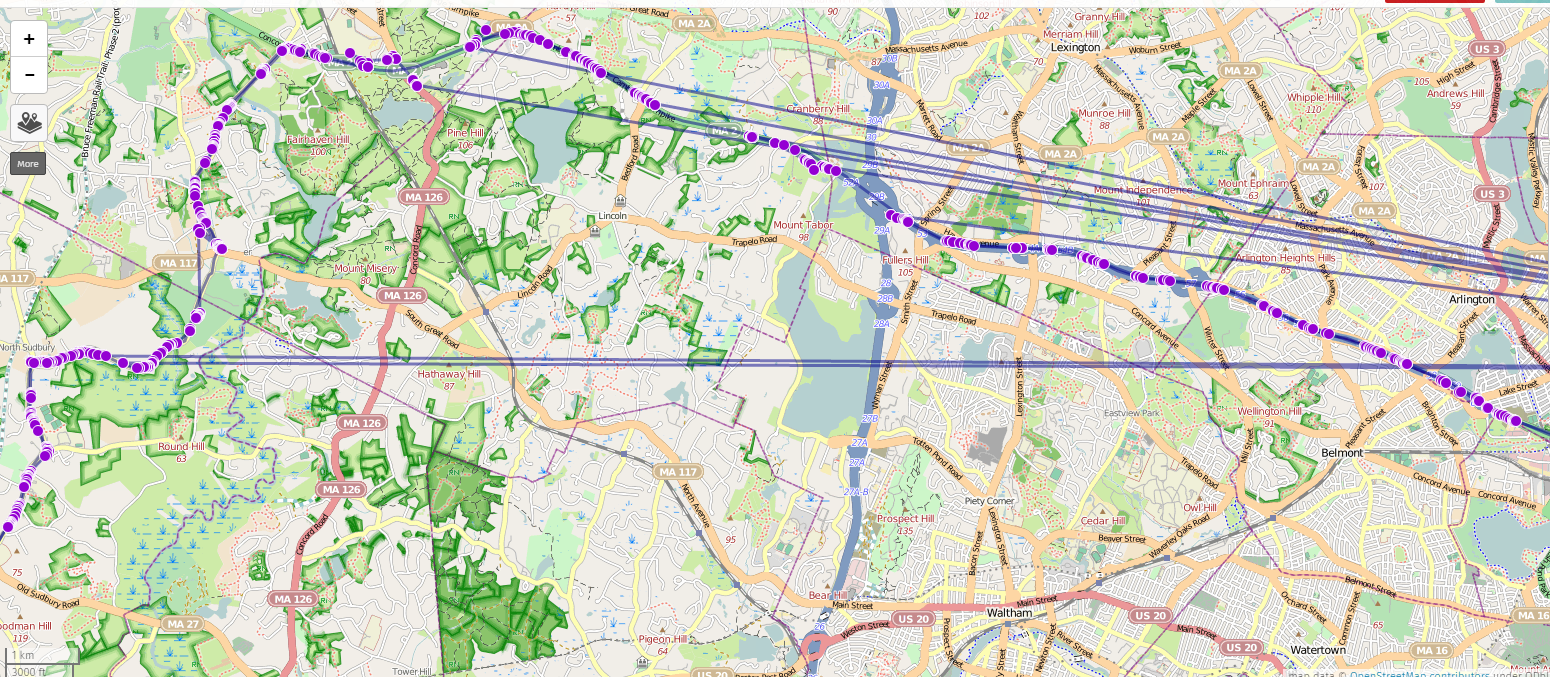
In this dataset, MLS would occasionally (typically at the fringes of reception with only a couple APs visible) return a completely bogus point, centered a few towns over, with an accuracy value of 5000.0 (I presume this is the maximum value, and represents not having any clue where you are). Every unknown point produced the same value, resulting in an odd-looking track that periodically jumps to an oddly-specific (and completely uninteresting) coordinate in Everett, MA, resulting in the odd radiants shown below. These bogus points are easily excluded by setting a floor on allowable accuracy values, which are intended to represent the radius of the “circle where you might actually be with 95% confidence, in meters”.
Summary
1) Can mere mortals (not Google) viably geolocate things using public WiFi data?
Totally! Admittedly, my sample set is very small and only covers a local urban area, but it’s clear that geolocating with MLS is very approachable for mortals. If you plan to make large numbers of requests at a time, they expect you to request an API key, and reserve the right to limit the number of daily requests, but API keys are currently provided free of charge. IIRC, numbers of requests that need to worry about API keys or limits are on the order of 20k/day; this requirement is mainly aimed at folks deploying popular apps and not individual tinkerers. For testing and small volume stuff, you can use “test” as an API key.
How good is it compared to GPS? Is it good enough to find your stuff?
So far, ranging from GPS-level accuracy to street-level accuracy (or “within a couple streets” if they are packed densely enough but not much WiFi is around). Generally, not as good as GPS. The estimated accuracy values ranged typically from 50-some to 250 or so meters, vs. a handful for GPS. Remember though, the accuracy circle represents a 95% confidence value, so there’s a decent chance the thing you’re looking for is closer to the middle than the edges. This might also depend on how big your thing is and how many places there are to look. In some cases, narrowing it down to your own distribution center might be enough.
2) Just how much WiFi is out there? How many open / captive portal hotspots? How many of them are vulnerable to DNS tunneling?
Like mentioned above, I found about 50% of points taken in a dense residential area were in-view of an access point susceptible to tunneling. In this area, the cable operator Comcast is largely – if inadvertently – responsible for this, so your mileage may vary in other areas (although I expect others to follow suit). In the last few years, Comcast has been replacing its “dumb” rental cable modems with ones that include a WiFi hotspot, which shows up unencrypted under the name ‘xfinitywifi’ and serves up a captive portal. The idea is that Comcast customers in the area can log into these and borrow bandwidth from other customers while on the go. Fortunately for us, so far it also means plenty of tunneling opportunities: ‘xfinitywifi’ represented nearly 50% of all APs in my local area, and 15% of a much larger dataset including upstate New York (this dataset has limited tunnel-probe data only and does not include location data). It also means Comcast – and other cablecos – could make an absolute killing selling low-cost IoT connectivity if they can provide a standardized machine-usable login method and minimal/no per-device-per-month access charges. An enterprise wishing to instrument stuff buys a single service package covering their entire fleet of devices and pays by the byte. Best of all, Comcast’s cable Internet customers already pay for nearly all of the infrastructure (bandwidth bills, electricity, climate-controlled housing of the access points…), so they can double-dip like a Chicago politician.
Under The Hood
There are a few practical challenges with this test approach that had to be dealt with:
The method used to manage the WiFi dongle (a Python library called ‘wifi‘) is a bit of a kludge that relies on scraping the output of commandline tools such as iwlist, iwconfig, etc and continually rewriting your /etc/network/interfaces file (probably via the aforementioned tools). This combination tends to fall over in a stiff wind, for example, if it encounters an access point with an empty SSID (”). Running headless, crashes are neither detectable or recoverable (except by plugcycling), so to keep things running, I had to add a check that avoids trying to connect to those APs. It turns out there are quite a few of them out there, so I’m probably missing a lot of tunneling opportunities and location resolution, but the data collected from the remaining ones is more than adequate for a proof-of-concept. I also added the step of replacing /etc/network/interfaces with a known-good backup copy at every startup, as a crash will leave it in an indeterminate state of disrepair, ensuring a fair chance the script will immediately crash again on the next run.
Keeping track of trips. A headless Pi plugged into the cig lighter and being power-cycled each time the car starts/stops will quickly mix data from multiple trips together in the database, and adding clock data would only compound the problem (as the clock is reset each time). The quick solution to this was don’t use a database adding a variable called the ‘runkey’ to the data for each trip. The runkey is a random number generated at script startup and associated with a single trip. To my mild surprise, I have gotten all unique random values despite the startup conditions being basically identical each time. Maybe the timing jitter in bringing up the wifi dongle is a better-than-nothing entropy source?
Connection attempts are time-consuming and blocking. At the start of this project, I wasn’t sure that connecting to random APs would even work at all at drive-by speeds. It does, but you kind of have to get lucky: DHCP takes some seconds (timeout set to 15), then the remaining evaluations take some further seconds each. Even with the hack of always preferring to connect to the strongest AP (assuming it is the closest and most likely to succeed), the odds of connecting are iffy. Luckily, my daily commute is the same every day, so repeated drives collect more data. Ordinarily, whatever AP I encounter ‘first’ would effectively shadow a bunch of others encountered shortly after, but the finite-retry mechanism ensures they are eventually excluded from consideration so that the others can be evaluated.
The blocking nature of the connection attempts also prevents WiFi location data (desired at fixed, ideally short intervals) from being collected reliably while tunnel probing. The easy solutions are to plop another Pi on the dashboard (sorry, fresh out!) or just toggle the script operating mode on a subsequent drive (I did the latter).
The iffyness of the connections may also explain a significant discrepancy between tunnel probes successfully received at my home server and APs reported as successful by the script side (meaning they sent the probe AND received a valid reply). Of course, I also found the outgoing responses would be eaten by Comcast if they contained certain characters (like ‘=’) in the fake domain name, even though the incoming probes containing them were unaffected.
One thing that hasn’t bitten me yet, oddly enough, is corruption of the Pi’s memory card, even though I am letting the power cut every time the car stops rather than have some way to cleanly shut down the headless Pi first. You really ought to shut it down first, but I’ve been lucky so far, and my current plan is to just reimage the card if/when it happens.
*DNS Tunneling
Typically, public WiFi hotspots, aka captive portals, are “open” (unsecured) access points, but not really open to the public – you can connect to it, but the first time you try to visit a website, you’re greeted with a login page instead.
DNS Tunneling is one technique for slipping modest amounts of data through many firewalls and other network-access blockades such as captive portals. How it works is the data, and any responses, are encoded as phony DNS lookup packets to and from a ‘special’ DNS server you control. The query consists mostly of your encoded data payload disguised as a really long domain name; likewise, any response is disguised as a DNS record response. Why it (usually) works is a bit of a longer story, but the short answer is that messing with DNS queries or responses yields a high chance of the client never being able to fetch a Web page, thus the access point never having the opportunity to feed a login page in its place, so the queries are let through unimpeded. If the access point simply blocked these queries for non-authenticated users, the HTTP request that follows would never occur; likewise, since hosts (by intention and design of the DNS) aggressively cache results, the access point feeding back bogus results for these initial queries would prevent web access even after the user logged in.
DNS tunneling is far from a new idea; the trick has been known since the mid to late ’90s and is used by some of the big players (PC and laptop vendors you’ve most certainly heard of) to push small amounts of tracking data past the firewall of whatever network their users might be connected to. However, it’s gained notoriety in the last few years as tools like iodine have evolved to push large enough amounts of data seamlessly enough to approximate a ‘normal’ internet connection.
Isn’t it illegal?
I am not a lawyer, and this is not legal advice, but my gut says “probably not”. Whether this is an officially sanctioned way to use the access point or not, the fact is it is intentionally left open for you to connect to (despite it being trivial to implement access controls such as turning on WPA(2) encryption, and the advice screamed from every mountaintop that you should do so), accepts your connection, then willfully passes your data and any response. The main thing that leaves me guess it’s on this side of the jail bar is that a bunch of well-known companies have been doing it for a long time on other peoples’ networks and not gotten into any sort of trouble for it. (Take that with a big grain of salt though; big companies have a knack for not getting in trouble for doing stuff that would get everyday schmucks up a creek.)
Doesn’t it open up the access point owner to all sorts of liability from anonymous ne’er-do-wells torrenting warez and other illegal stuff through it?
Not really. The ‘tunneling’ part is key; the other end of the tunnel is where the ne’er-do-well’s traffic will appear to originate from; that’s a server they control. Unless they are complete idiots, the traffic within the tunnel is encrypted, and it’s essentially the same thing as a VPN connection. Anyone with a good reason to track down the owner of that server will follow the money trail in a similar way. While a clever warez d00d will attempt to hide their trail using a torrent-VPN type service offered from an obscure country and pay for it in bitcoins, the trail will at least not point to the access point owner.
So it’s just a free-for-all then?
No; there are at least a few technical measures an access point designer/owner can take against this technique. An easy and safe one is to severely throttle or rate-limit DNS traffic for unauthenticated users. While this won’t stop it outright, it will limit any bandwidth consumption to a negligible level, and the ‘abuse’ to a largely philosophical one (somebody deriving a handful of bytes/sec worth of benefit without paying for it). The ratelimit could get increasingly aggressive the longer the user is connected without authenticating. Another is to intercept A record responses and feed back fake ones anyway (e.g. virtual IPs in a private address range, e.g. 10.x.x.x), with the caveat that the AP then must store the association between the fake address it handed out and the real one, and once the user is authenticated, forward traffic for it for the life of the session. I wouldn’t recommend this approach as it may still have consequences for the client once they connect to a different access point and the (now cached) 10.x.x.x address is no longer valid, but I’ve seen it done. Finally, you can target the worst offenders pretty easily, as they (via software such as iodine) are pushing large volumes of requests for e.g. TXT records (human-readable text records which can hold larger data payloads) instead of A records (IP address lookups). However, some modern internet functionality such as email anti-spam measures (e.g. SPF) do legitimately rely on TXT record lookup, so proceed with caution. Finally, statistical methods could be used – again, the hardcore methods like iodine will attempt to max out the length AND compress hell out of the payloads, so heuristics based on average hostname lookup length and entropy analysis of the contents could work. This is more involved though, deep packet inspection territory, and as with any statistical method runs the risk of false positives and negatives.
Leave a Reply